- By Binxu Wang and John Vastola (From github).
- From https://yang-song.net/blog/2021/score/
- From https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- From (original): https://pantelis.github.io/aiml-common/lectures/stable-diffusion/harvard-tutorial/Diffusion_Model_with_Cross_Attention_(student).html
- This tutorial is being re-written: Tutorial: Stable Diffusion from Scratch II

In particular, you will implement parts of:
- basic 1D forward/reverse diffusion
- a U-Net architecture for working with images
- the loss associated with learning the score function
- an attention model for conditional generation
- an autoencoder
We need a reasonably small dataset so that training does not take forever, so we will be working with MNIST, a set of 28x28 images of handwritten 0-9 digits. By the end, our model should be able to take in a number prompt (e.g. “4”) and output an image of the digit 4.
!pip install einops
!pip install lpips
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import functools
from torch.optim import Adam
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import MNIST
import tqdm
from tqdm.notebook import trange, tqdm
from torch.optim.lr_scheduler import MultiplicativeLR, LambdaLR
import matplotlib.pyplot as plt
from torchvision.utils import make_grid1. Basic forward/reverse diffusion
This section reviews material from the previous MLFS seminar on diffusion generative models. Skip this if you already know the basics!
The gist is that our generative model will work in the following way. We will take our training examples (e.g. images) and corrupt them with noise until they are unrecognizable. Then we will learn to `denoise’ them, and potentially turn pure noise into something similar to what we started with.
Basic forward diffusion
Let’s start with forward diffusion. In the simplest case, the relevant diffusion equation is

Implement the missing part of 1D forward diffusion.
Hint: You can use np.random.randn() to generate random numbers.
# Simulate forward diffusion for N steps.
def forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt):
"""x0: initial sample value, scalar
noise_strength_fn: function of time, outputs scalar noise strength
t0: initial time
nsteps: number of diffusion steps
dt: time step size
"""
# Initialize trajectory
x = np.zeros(nsteps + 1); x[0] = x0
t = t0 + np.arange(nsteps + 1)*dt
# Perform many Euler-Maruyama time steps
for i in range(nsteps):
noise_strength = noise_strength_fn(t[i])
############ YOUR CODE HERE (2 lines)
random_normal = ...
x[i+1] = ...
#####################################
return x, t
# Example noise strength function: always equal to 1
def noise_strength_constant(t):
return 1See if it works by running the code below.
nsteps = 100
t0 = 0
dt = 0.1
noise_strength_fn = noise_strength_constant
x0 = 0
num_tries = 5
for i in range(num_tries):
x, t = forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt)
plt.plot(t, x)
plt.xlabel('time', fontsize=20)
plt.ylabel('$x$', fontsize=20)
plt.title('Forward diffusion visualized', fontsize=20)
plt.show()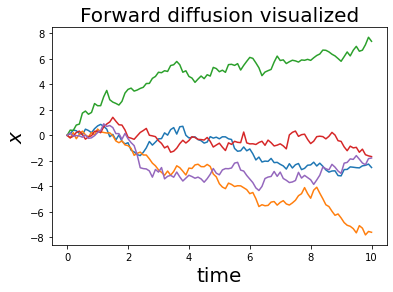
Basic reverse diffusion
We can reverse this diffusion process by a similar-looking update rule:

Implement the missing part of 1D reverse diffusion. You will test it with the above score function.
Hint: You can use np.random.randn() to generate random numbers.
# Simulate forward diffusion for N steps.
def reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt):
"""x0: initial sample value, scalar
noise_strength_fn: function of time, outputs scalar noise strength
score_fn: score function
T: final time
nsteps: number of diffusion steps
dt: time step size
"""
# Initialize trajectory
x = np.zeros(nsteps + 1); x[0] = x0
t = np.arange(nsteps + 1)*dt
# Perform many Euler-Maruyama time steps
for i in range(nsteps):
noise_strength = noise_strength_fn(T - t[i])
score = score_fn(x[i], 0, noise_strength, T-t[i])
############ YOUR CODE HERE (2 lines)
random_normal = ...
x[i+1] = ...
#####################################
return x, t
# Example noise strength function: always equal to 1
def score_simple(x, x0, noise_strength, t):
score = - (x-x0)/((noise_strength**2)*t)
return scoreRun the cell below to see if your implementation works.
nsteps = 100
t0 = 0
dt = 0.1
noise_strength_fn = noise_strength_constant
score_fn = score_simple
x0 = 0
T = 11
num_tries = 5
for i in range(num_tries):
x0 = np.random.normal(loc=0, scale=T) # draw from the noise distribution, which is diffusion for time T w noise strength 1
x, t = reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt)
plt.plot(t, x)
plt.xlabel('time', fontsize=20)
plt.ylabel('$x$', fontsize=20)
plt.title('Reverse diffusion visualized', fontsize=20)
plt.show()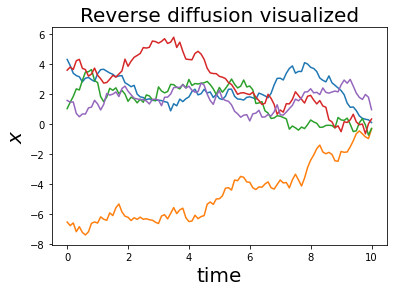
Basic score function learning
In practice, we don’t already know the score function; instead, we have to learn it. One way to learn it is to train a neural network to `denoise’ samples via the denoising objective

2. Working with images via U-Nets
We just reviewed the very basics of diffusion models, with the takeaway that learning the score function allows us to turn pure noise into something interesting. We will learn to approximate the score function with a neural network. But when we are working with images, we need our neural network to ‘play nice’ with them, and to reflect inductive biases we associate with images.
A reasonable choice is to choose the neural network architecture to be that of a U-Net, which combines a CNN-like structure with downscaling/upscaling operations that help the network pay attention to features of images at different spatial scales.
Since the score function we’re trying to learn is a function of time, we also need to come up with a way to make sure our neural network properly responds to changes in time. For this purpose, we can use a time embedding.
In this section, you will fill in some missing U-Net pieces.
Helping our neural network work with time
The below code helps our neural network work with time via a time embedding. The idea is that, instead of just telling our network one number (the current time), we express the current time in terms of a large number of sinusoidal features. The hope is that, if we tell our network the current time in many different ways, it will more easily respond to changes in time.
This will enable us to successfully learn a time-dependent score function s(x,t).
#@title Get some modules to let time interact
class GaussianFourierProjection(nn.Module):
"""Gaussian random features for encoding time steps."""
def __init__(self, embed_dim, scale=30.):
super().__init__()
# Randomly sample weights (frequencies) during initialization.
# These weights (frequencies) are fixed during optimization and are not trainable.
self.W = nn.Parameter(torch.randn(embed_dim // 2) * scale, requires_grad=False)
def forward(self, x):
# Cosine(2 pi freq x), Sine(2 pi freq x)
x_proj = x[:, None] * self.W[None, :] * 2 * np.pi
return torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
class Dense(nn.Module):
"""A fully connected layer that reshapes outputs to feature maps.
Allow time repr to input additively from the side of a convolution layer.
"""
def __init__(self, input_dim, output_dim):
super().__init__()
self.dense = nn.Linear(input_dim, output_dim)
def forward(self, x):
return self.dense(x)[..., None, None]
# this broadcast the 2d tensor to 4d, add the same value across space.Defining the U-Net architecture
The below class defines a U-Net architecture. Fill in the missing pieces. (This shouldn’t be hard; mainly, it’s to get you to look at the structure.)
#@title Defining a time-dependent score-based model (double click to expand or collapse)
class UNet(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""Initialize a time-dependent score-based network.
Args:
marginal_prob_std: A function that takes time t and gives the standard
deviation of the perturbation kernel p_{0t}(x(t) | x(0)).
channels: The number of channels for feature maps of each resolution.
embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
########### YOUR CODE HERE (3 lines)
self.conv3 = ...
self.dense3 = ...
self.gnorm3 = ...
#########################
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2] + channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1] + channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0] + channels[0], 1, 3, stride=1)
# The swish activation function
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
## Incorporate information from t
## Group normalization
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
########## YOUR CODE HERE (2 lines)
h3 = ... # conv, dense
# apply activation function
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
############
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# Decoding path
h = self.tconv4(h4)
## Skip connection from the encoding path
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(torch.cat([h, h3], dim=1))
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(torch.cat([h, h2], dim=1))
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(torch.cat([h, h1], dim=1))
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hBelow is code for an alternate U-Net architecture. Apparently, diffusion models can be successful with somewhat different architectural details. (Note that the differences from the above class are kind of subtle, though.)
- Upper one, concatenate the tensor from the down block for skip connection.
- Lower one, directly add the tensor from the down blocks for skip connection.
- A special case of the upper
#@title Alternative time-dependent score-based model (double click to expand or collapse)
class UNet_res(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""Initialize a time-dependent score-based network.
Args:
marginal_prob_std: A function that takes time t and gives the standard
deviation of the perturbation kernel p_{0t}(x(t) | x(0)).
channels: The number of channels for feature maps of each resolution.
embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1) # + channels[2]
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1) # + channels[1]
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1) # + channels[0]
# The swish activation function
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
## Incorporate information from t
## Group normalization
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# Decoding path
h = self.tconv4(h4)
## Skip connection from the encoding path
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3)
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2)
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hTips: When you feel uncertain about the shape of the tensors throughout the layers, define the layers outside and see the shapes. This format could be helpful.
net = nn.Sequential(
nn.Conv2d(...),
nn.ConvTranspose2d(...),
)
x = torch.randn(...)
for l in net:
x = layer(x)
print(x.shape)3. Train the U-Net to learn a score function
Let’s combine the U-Net we just defined with a way to learn the score function. We need to define a loss function, and then train a neural network in the usual way.
In the next cell, we will define the specific forward diffusion process

#@title Diffusion constant and noise strength
device = 'cuda' #@param ['cuda', 'cpu'] {'type':'string'}
def marginal_prob_std(t, sigma):
"""Compute the mean and standard deviation of $p_{0t}(x(t) | x(0))$.
Args:
t: A vector of time steps.
sigma: The $\sigma$ in our SDE.
Returns:
The standard deviation.
"""
t = torch.tensor(t, device=device)
return torch.sqrt((sigma**(2 * t) - 1.) / 2. / np.log(sigma))
def diffusion_coeff(t, sigma):
"""Compute the diffusion coefficient of our SDE.
Args:
t: A vector of time steps.
sigma: The $\sigma$ in our SDE.
Returns:
The vector of diffusion coefficients.
"""
return torch.tensor(sigma**t, device=device)
sigma = 25.0#@param {'type':'number'}
marginal_prob_std_fn = functools.partial(marginal_prob_std, sigma=sigma)
diffusion_coeff_fn = functools.partial(diffusion_coeff, sigma=sigma)Defining the loss function
The loss function is mostly defined below. You need to add one part: sample random noise with strength std[:, None, None, None], and make sure it has the same shape as x. Then use this to perturb x.
Hint: torch.randn_like() may be useful.
def loss_fn(model, x, marginal_prob_std, eps=1e-5):
"""The loss function for training score-based generative models.
Args:
model: A PyTorch model instance that represents a
time-dependent score-based model.
x: A mini-batch of training data.
marginal_prob_std: A function that gives the standard deviation of
the perturbation kernel.
eps: A tolerance value for numerical stability.
"""
# Sample time uniformly in 0, 1
random_t = torch.rand(x.shape[0], device=x.device) * (1. - eps) + eps
# Find the noise std at the time `t`
std = marginal_prob_std(random_t)
####### YOUR CODE HERE (2 lines)
z = ... # get normally distributed noise
perturbed_x = x + ...
##############
score = model(perturbed_x, random_t)
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1,2,3)))
return lossDefining the sampler
#@title Sampler code
num_steps = 500#@param {'type':'integer'}
def Euler_Maruyama_sampler(score_model,
marginal_prob_std,
diffusion_coeff,
batch_size=64,
x_shape=(1, 28, 28),
num_steps=num_steps,
device='cuda',
eps=1e-3, y=None):
"""Generate samples from score-based models with the Euler-Maruyama solver.
Args:
score_model: A PyTorch model that represents the time-dependent score-based model.
marginal_prob_std: A function that gives the standard deviation of
the perturbation kernel.
diffusion_coeff: A function that gives the diffusion coefficient of the SDE.
batch_size: The number of samplers to generate by calling this function once.
num_steps: The number of sampling steps.
Equivalent to the number of discretized time steps.
device: 'cuda' for running on GPUs, and 'cpu' for running on CPUs.
eps: The smallest time step for numerical stability.
Returns:
Samples.
"""
t = torch.ones(batch_size, device=device)
init_x = torch.randn(batch_size, *x_shape, device=device) \
* marginal_prob_std(t)[:, None, None, None]
time_steps = torch.linspace(1., eps, num_steps, device=device)
step_size = time_steps[0] - time_steps[1]
x = init_x
with torch.no_grad():
for time_step in tqdm(time_steps):
batch_time_step = torch.ones(batch_size, device=device) * time_step
g = diffusion_coeff(batch_time_step)
mean_x = x + (g**2)[:, None, None, None] * score_model(x, batch_time_step, y=y) * step_size
x = mean_x + torch.sqrt(step_size) * g[:, None, None, None] * torch.randn_like(x)
# Do not include any noise in the last sampling step.
return mean_xTraining on MNIST
We will train on MNIST, and learn to generate pictures that look like 0-9 digits. No code to fill in here; just run it and see if it works!
In the following code, the loss could descent to ~ 40-50.
#@title Training (double click to expand or collapse)
score_model = torch.nn.DataParallel(UNet(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
n_epochs = 50#@param {'type':'integer'}
## size of a mini-batch
batch_size = 2048 #@param {'type':'integer'}
## learning rate
lr=5e-4 #@param {'type':'number'}
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
optimizer = Adam(score_model.parameters(), lr=lr)
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for x, y in tqdm(data_loader):
x = x.to(device)
loss = loss_fn(score_model, x, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(score_model.state_dict(), 'ckpt.pth')In the following code, the loss could descent to ~ 25, with relatively good quality.
#@title Training the alternate U-Net model (double click to expand or collapse)
score_model = torch.nn.DataParallel(UNet_res(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
n_epochs = 75#@param {'type':'integer'}
## size of a mini-batch
batch_size = 1024 #@param {'type':'integer'}
## learning rate
lr=10e-4 #@param {'type':'number'}
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
optimizer = Adam(score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for x, y in data_loader:
x = x.to(device)
loss = loss_fn(score_model, x, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(score_model.state_dict(), 'ckpt_res.pth')Visualize the results of training below.
## Load the pre-trained checkpoint from disk.
device = 'cuda' #@param ['cuda', 'cpu'] {'type':'string'}
# ckpt = torch.load('ckpt.pth', map_location=device)
# score_model.load_state_dict(ckpt)
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 500 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
## Generate samples using the specified sampler.
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=None)
## Sample visualization.
samples = samples.clamp(0.0, 1.0)
%matplotlib inline
import matplotlib.pyplot as plt
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
def save_samples_uncond(score_model, suffix=""):
score_model.eval()
## Generate samples using the specified sampler.
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 250 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
# score_model.eval()
## Generate samples using the specified sampler.
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
)
## Sample visualization.
samples = samples.clamp(0.0, 1.0)
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
sample_np = sample_grid.permute(1, 2, 0).cpu().numpy()
plt.imsave(f"uncondition_diffusion{suffix}.png", sample_np,)
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_np, vmin=0., vmax=1.)
plt.show()
uncond_score_model = torch.nn.DataParallel(UNet_res(marginal_prob_std=marginal_prob_std_fn))
uncond_score_model.load_state_dict(torch.load("ckpt_res.pth"))
save_samples_uncond(uncond_score_model, suffix="_res")
4. Using attention to get conditional generation to work
In addition to generating images of e.g. 0-9 digits, we would like to do conditional generation: we would like to specify which digit we would like to generate an image of, for example.
Attention models, while not strictly necessary for conditional generation, have proven useful for getting it to work well. In this section, you will implement parts of an attention model.
from einops import rearrange
import math“Word embedding” of digits
Here, instead of using a fancy CLIP model, we just define our own vector representations of the digits 0-9.
We used the nn.Embedding layer to turn 0-9 index into vectors.
class WordEmbed(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(WordEmbed, self).__init__()
self.embed = nn.Embedding(vocab_size+1, embed_dim)
def forward(self, ids):
return self.embed(ids)Let’s develop our Attention layer
We usually implement attention models using 3 parts: * CrossAttention Write a module to do self / cross attention for sequences. * TransformerBlock Combine self/cross-attention and a feed-forward neural network. * SpatialTransformer To use attention in a U-net, transform the spatial tensor to a sequential tensor and back.
You will implement a part of the CrossAttention class, and you will also pick where to add attention in your U-Net.
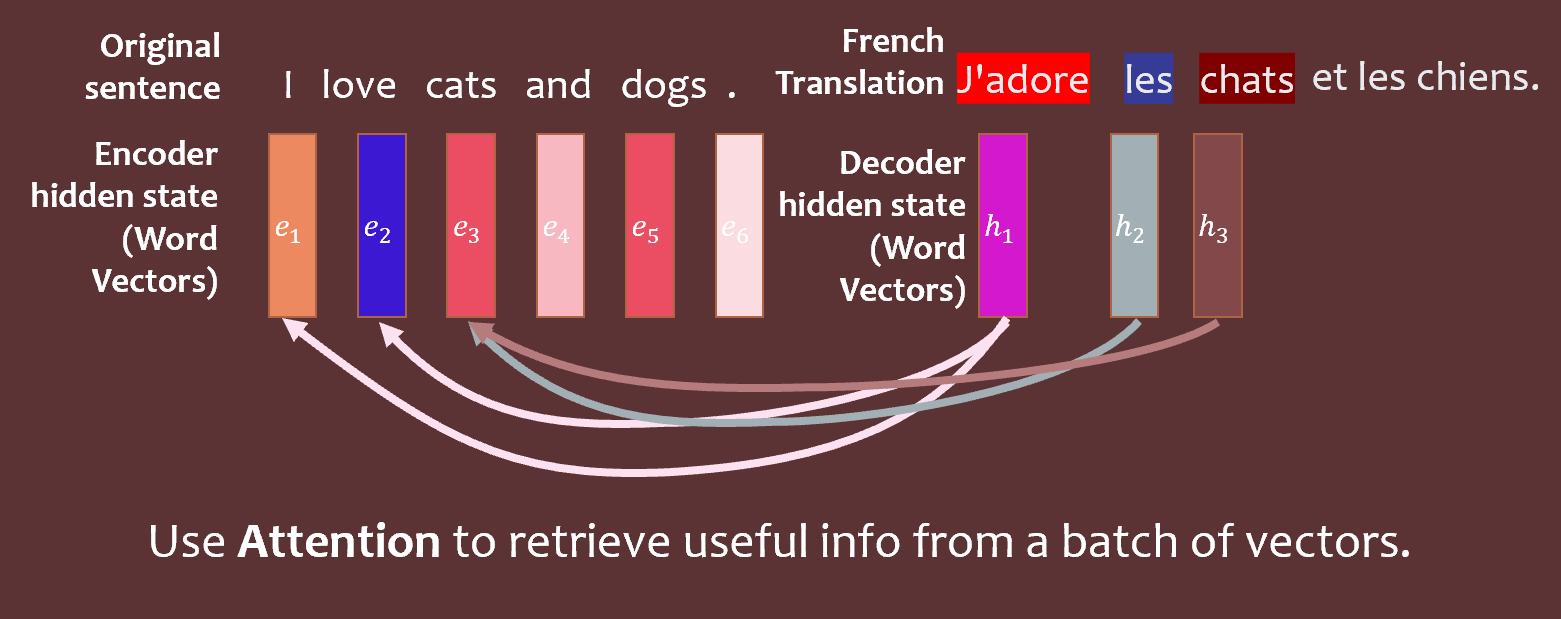
Here’s a brief review of the mathematics of attention models. QKV (query-key-value) attention models represent queries, keys, and values as vectors. These are tools that help us relate words/images on one side of a translation task to the other side.
These are linearly related to e vectors (which represent the hidden state of the encoder) and h vectors (which represent the hidden state of the decoder):

Implement the missing pieces of the CrossAttention class below. Also implement the missing part of the TransformerBlock class.
Note that the relevant matrix multiplications can be performed using torch.einsum. For example, to multiply an M×N matrix A together with an N×N matrix B, i.e. to obtain AB, we can write:
torch.einsum(ij,jk -> ik ,A, B)
If, instead, we wanted to compute ABT, we could write
torch.einsum(ij,kj->ik ,A, B)
The library takes care of moving the dimensions around properly. For machine learning, it is often important to do operations like matrix multiplication in batches. In this case, you can might have tensors instead of matrices, but you can write a very similar expression:
torch.einsum(bij,bkj ,A, B)
where b here is the index that describes which batch elements we are talking about. As a final point, you can use whatever letters you like instead of i, j, etc.
Hint: F.softmax may also be helpful!
Attention Modules
class CrossAttention(nn.Module):
def __init__(self, embed_dim, hidden_dim, context_dim=None, num_heads=1,):
"""
Note: For simplicity reason, we just implemented 1-head attention.
Feel free to implement multi-head attention! with fancy tensor manipulations.
"""
super(CrossAttention, self).__init__()
self.hidden_dim = hidden_dim
self.context_dim = context_dim
self.embed_dim = embed_dim
self.query = nn.Linear(hidden_dim, embed_dim, bias=False)
if context_dim is None:
self.self_attn = True
self.key = nn.Linear(hidden_dim, embed_dim, bias=False) ###########
self.value = nn.Linear(hidden_dim, hidden_dim, bias=False) ############
else:
self.self_attn = False
self.key = nn.Linear(context_dim, embed_dim, bias=False) #############
self.value = nn.Linear(context_dim, hidden_dim, bias=False) ############
def forward(self, tokens, context=None):
# tokens: with shape [batch, sequence_len, hidden_dim]
# context: with shape [batch, contex_seq_len, context_dim]
if self.self_attn:
Q = self.query(tokens)
K = self.key(tokens)
V = self.value(tokens)
else:
# implement Q, K, V for the Cross attention
Q = ...
K = ...
V = ...
#print(Q.shape, K.shape, V.shape)
####### YOUR CODE HERE (2 lines)
scoremats = ... # inner product of Q and K, a tensor
attnmats = ... # softmax of scoremats
#print(scoremats.shape, attnmats.shape, )
ctx_vecs = torch.einsum("BTS,BSH->BTH", attnmats, V) # weighted average value vectors by attnmats
return ctx_vecs
class TransformerBlock(nn.Module):
"""The transformer block that combines self-attn, cross-attn and feed forward neural net"""
def __init__(self, hidden_dim, context_dim):
super(TransformerBlock, self).__init__()
self.attn_self = CrossAttention(hidden_dim, hidden_dim, )
self.attn_cross = CrossAttention(hidden_dim, hidden_dim, context_dim)
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
self.norm3 = nn.LayerNorm(hidden_dim)
# implement a 2 layer MLP with K*hidden_dim hidden units, and nn.GeLU nonlinearity #######
self.ffn = nn.Sequential(
# YOUR CODE HERE ##################
...
)
def forward(self, x, context=None):
# Notice the + x as residue connections
x = self.attn_self(self.norm1(x)) + x
# Notice the + x as residue connections
x = self.attn_cross(self.norm2(x), context=context) + x
# Notice the + x as residue connections
x = self.ffn(self.norm3(x)) + x
return x
class SpatialTransformer(nn.Module):
def __init__(self, hidden_dim, context_dim):
super(SpatialTransformer, self).__init__()
self.transformer = TransformerBlock(hidden_dim, context_dim)
def forward(self, x, context=None):
b, c, h, w = x.shape
x_in = x
# Combine the spatial dimensions and move the channel dimen to the end
x = rearrange(x, "b c h w->b (h w) c")
# Apply the sequence transformer
x = self.transformer(x, context)
# Reverse the process
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
# Residue
return x + x_inCode play ground!
Putting it together, UNet Transformer
Now you can interleave your SpatialTransformer layers with the convolutional layers!
Remember to use them in your forward function. Look at the architecture, and add in extra attention layers if you wish.
class UNet_Tranformer(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256,
text_dim=256, nClass=10):
"""Initialize a time-dependent score-based network.
Args:
marginal_prob_std: A function that takes time t and gives the standard
deviation of the perturbation kernel p_{0t}(x(t) | x(0)).
channels: The number of channels for feature maps of each resolution.
embed_dim: The dimensionality of Gaussian random feature embeddings of time.
text_dim: the embedding dimension of text / digits.
nClass: number of classes you want to model.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.attn3 = SpatialTransformer(channels[2], text_dim)
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# YOUR CODE: interleave some attention layers with conv layers
self.attn4 = ... ######################################
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1) # + channels[2]
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1) # + channels[1]
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1) # + channels[0]
# The swish activation function
self.act = nn.SiLU() # lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
self.cond_embed = nn.Embedding(nClass, text_dim)
def forward(self, x, t, y=None):
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
y_embed = self.cond_embed(y).unsqueeze(1)
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
## Incorporate information from t
## Group normalization
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h3 = self.attn3(h3, y_embed) # Use your attention layers
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# Your code: Use your additional attention layers!
h4 = ... ##################### ATTENTION LAYER COULD GO HERE IF ATTN4 IS DEFINED
# Decoding path
h = self.tconv4(h4) + self.dense5(embed)
## Skip connection from the encoding path
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3) + self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2) + self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hConditional Denoising Loss
Here, we need to modify the loss function by using the y information in the training.
def loss_fn_cond(model, x, y, marginal_prob_std, eps=1e-5):
"""The loss function for training score-based generative models.
Args:
model: A PyTorch model instance that represents a
time-dependent score-based model.
x: A mini-batch of training data.
marginal_prob_std: A function that gives the standard deviation of
the perturbation kernel.
eps: A tolerance value for numerical stability.
"""
random_t = torch.rand(x.shape[0], device=x.device) * (1. - eps) + eps
z = torch.randn_like(x)
std = marginal_prob_std(random_t)
perturbed_x = x + z * std[:, None, None, None]
score = model(perturbed_x, random_t, y=y)
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1,2,3)))
return lossTraining a model that includes attention
The below code, similar to code above, does the training.
#@title Training model
continue_training = False #@param {type:"boolean"}
if not continue_training:
print("initilize new score model...")
score_model = torch.nn.DataParallel(UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
n_epochs = 100#@param {'type':'integer'}
## size of a mini-batch
batch_size = 1024 #@param {'type':'integer'}
## learning rate
lr=10e-4 #@param {'type':'number'}
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
optimizer = Adam(score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for x, y in tqdm(data_loader):
x = x.to(device)
loss = loss_fn_cond(score_model, x, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(score_model.state_dict(), 'ckpt_transformer.pth')Loss around 23 at 67 epochs (without lr tuning, around 150 epochs reach 23)
#@title A handy training function
def train_diffusion_model(dataset,
score_model,
n_epochs = 100,
batch_size = 1024,
lr=10e-4,
model_name="transformer"):
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
optimizer = Adam(score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for x, y in tqdm(data_loader):
x = x.to(device)
loss = loss_fn_cond(score_model, x, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(score_model.state_dict(), f'ckpt_{model_name}.pth')
# Feel free to play with hyperparameters for training!
score_model = torch.nn.DataParallel(UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
train_diffusion_model(dataset, score_model,
n_epochs = 100,
batch_size = 1024,
lr=10e-4,
model_name="transformer")
def visualize_digit_embedding(digit_embed):
cossim_mat = []
for i in range(10):
cossim = torch.cosine_similarity(digit_embed, digit_embed[i:i+1,:]).cpu()
cossim_mat.append(cossim)
cossim_mat = torch.stack(cossim_mat)
cossim_mat_nodiag = cossim_mat + torch.diag_embed(torch.nan * torch.ones(10))
plt.imshow(cossim_mat_nodiag)
plt.show()
return cossim_mat
cossim_mat = visualize_digit_embedding(score_model.module.cond_embed.weight.data)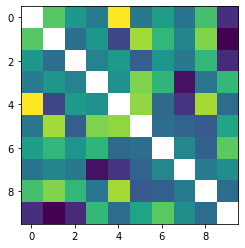
Examine Samples
Here is some code we can use to see how well the model does conditional generation. You can use the menu on the right to choose what you want to generate.
## Load the pre-trained checkpoint from disk.
# device = 'cuda' #@param ['cuda', 'cpu'] {'type':'string'}
# ckpt = torch.load('ckpt.pth', map_location=device)
# score_model.load_state_dict(ckpt)
digit = 4 #@param {'type':'integer'}
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 250 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
# score_model.eval()
## Generate samples using the specified sampler.
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
samples = samples.clamp(0.0, 1.0)
%matplotlib inline
import matplotlib.pyplot as plt
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
def save_samples_cond(score_model, suffix):
score_model.eval()
for digit in range(10):
## Generate samples using the specified sampler.
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 500 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
# score_model.eval()
## Generate samples using the specified sampler.
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
samples = samples.clamp(0.0, 1.0)
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
sample_np = sample_grid.permute(1, 2, 0).cpu().numpy()
plt.imsave(f"condition_diffusion{suffix}_digit%d.png"%digit, sample_np,)
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_np, vmin=0., vmax=1.)
plt.show() |
 |
 |
 |
 |
 |
 |
 |
 |
 |
save_samples_cond(score_model) # model without res connection |
 |
 |
 |
 |
 |
 |
 |
 |
 |
5. Latent space diffusion using an autoencoder
Finally, we get to one of the most important contributions of Rombach et al., the paper behind Stable Diffusion! Instead of diffusing in pixel space (i.e. corrupting and denoising each pixel of an image), we can try diffusing in some kind of latent space.
This has a few advantages. An obvious one is speed: compressing images before doing forward/reverse diffusion on them makes both generation and training faster. Another advantage is that the latent space, if carefully chosen, may be a more natural or interpretable space for working with images. For example, given a set of pictures of heads, perhaps some latent direction corresponds to head direction.
If we do not have any a priori bias towards one latent space or another, we can just throw an autoencoder at the problem and hope it comes up with something appropriate.
In this section, we will use an autoencoder to compress MNIST images to a smaller scale, and glue this to the rest of our diffusion pipeline.
Defining the autoencoder
Complete the missing part of the autoencoder’s forward function. Note that what an autoencoder does is first ‘encode’ an image into some latent representation, and then ‘decode’ an image from that latent representation.
Hint: You can access the encoder and decoder via self.encoder and self.decoder.
class AutoEncoder(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, channels=[4, 8, 32],):
"""Initialize a time-dependent score-based network.
Args:
channels: The number of channels for feature maps of each resolution.
embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
# Encoding layers where the resolution decreases
self.encoder = nn.Sequential(nn.Conv2d(1, channels[0], 3, stride=1, bias=True),
nn.BatchNorm2d(channels[0]),
nn.SiLU(),
nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=True),
nn.BatchNorm2d(channels[1]),
nn.SiLU(),
nn.Conv2d(channels[1], channels[2], 3, stride=1, bias=True),
nn.BatchNorm2d(channels[2]),
) #nn.SiLU(),
self.decoder = nn.Sequential(nn.ConvTranspose2d(channels[2], channels[1], 3, stride=1, bias=True),
nn.BatchNorm2d(channels[1]),
nn.SiLU(),
nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=True, output_padding=1),
nn.BatchNorm2d(channels[0]),
nn.SiLU(),
nn.ConvTranspose2d(channels[0], 1, 3, stride=1, bias=True),
nn.Sigmoid(),)
def forward(self, x):
########## YOUR CODE HERE (1 line)
output = ...
###################
return outputThe following code checks to see whether your autoencoder was defined properly.
x_tmp = torch.randn(1,1,28,28)
print(AutoEncoder()(x_tmp).shape)
assert AutoEncoder()(x_tmp).shape == x_tmp.shape, "Check conv layer spec! the autoencoder input output shape not align"Train the autoencoder with the help of a perceptual loss
Let’s train the autoencoder on MNIST images! Do this by running the cells below.
The loss could be really small ~ close to 0.01
from lpips import LPIPS
# Define the loss function, MSE and LPIPS
lpips = LPIPS(net="squeeze").cuda()
loss_fn_ae = lambda x,xhat: \
nn.functional.mse_loss(x, xhat) + \
lpips(x.repeat(1,3,1,1), x_hat.repeat(1,3,1,1)).mean()
ae_model = AutoEncoder([4, 4, 4]).cuda()
n_epochs = 50 #@param {'type':'integer'}
## size of a mini-batch
batch_size = 2048 #@param {'type':'integer'}
## learning rate
lr=10e-4 #@param {'type':'number'}
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=0)
optimizer = Adam(ae_model.parameters(), lr=lr)
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for x, y in data_loader:
x = x.to(device)
z = ae_model.encoder(x)
x_hat = ae_model.decoder(z)
loss = loss_fn_ae(x, x_hat) #loss_fn_cond(score_model, x, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
print('{} Average Loss: {:5f}'.format(epoch, avg_loss / num_items))
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(ae_model.state_dict(), 'ckpt_ae.pth')The below cell visualizes the results. The autoencoder’s output should look almost identical to the original images.
#@title Visualize trained autoencoder
ae_model.eval()
x, y = next(iter(data_loader))
x_hat = ae_model(x.to(device)).cpu()
plt.figure(figsize=(6,6.5))
plt.axis('off')
plt.imshow(make_grid(x[:64,:,:,:].cpu()).permute([1,2,0]), vmin=0., vmax=1.)
plt.title("Original")
plt.show()
plt.figure(figsize=(6,6.5))
plt.axis('off')
plt.imshow(make_grid(x_hat[:64,:,:,:].cpu()).permute([1,2,0]), vmin=0., vmax=1.)
plt.title("AE Reconstructed")
plt.show()Create latent state dataset
Let’s use our autoencoder to convert MNIST images into a latent space representation. We will use these compressed images to train our diffusion generative model.
batch_size = 4096
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=False, num_workers=4)
ae_model.requires_grad_(False)
ae_model.eval()
zs = []
ys = []
for x, y in tqdm(data_loader):
z = ae_model.encoder(x.to(device)).cpu()
zs.append(z)
ys.append(y)
zdata = torch.cat(zs, )
ydata = torch.cat(ys, )print(zdata.shape)
print(ydata.shape)
print(zdata.mean(), zdata.var())
# torch.Size([60000, 4, 10, 10])
# torch.Size([60000])
# tensor(-0.0616) tensor(0.9521)
from torch.utils.data import TensorDataset
latent_dataset = TensorDataset(zdata, ydata)Transformer UNet model for Latents
Here is a U-Net (that includes self/cross-attention) similar to the one we defined before, but that this time works with compressed images instead of full-size images. You don’t need to do anything here except take a look at the architecture.
class Latent_UNet_Tranformer(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, marginal_prob_std, channels=[4, 64, 128, 256], embed_dim=256,
text_dim=256, nClass=10):
"""Initialize a time-dependent score-based network.
Args:
marginal_prob_std: A function that takes time t and gives the standard
deviation of the perturbation kernel p_{0t}(x(t) | x(0)).
channels: The number of channels for feature maps of each resolution.
embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim))
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(channels[0], channels[1], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[1])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[1])
self.conv2 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[2])
self.gnorm2 = nn.GroupNorm(4, num_channels=channels[2])
self.attn2 = SpatialTransformer(channels[2], text_dim)
self.conv3 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[3])
self.gnorm3 = nn.GroupNorm(4, num_channels=channels[3])
self.attn3 = SpatialTransformer(channels[3], text_dim)
self.tconv3 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False, )
self.dense6 = Dense(embed_dim, channels[2])
self.tgnorm3 = nn.GroupNorm(4, num_channels=channels[2])
self.attn6 = SpatialTransformer(channels[2], text_dim)
self.tconv2 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1) # + channels[2]
self.dense7 = Dense(embed_dim, channels[1])
self.tgnorm2 = nn.GroupNorm(4, num_channels=channels[1])
self.tconv1 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=1) # + channels[1]
# The swish activation function
self.act = nn.SiLU() # lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
self.cond_embed = nn.Embedding(nClass, text_dim)
def forward(self, x, t, y=None):
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
y_embed = self.cond_embed(y).unsqueeze(1)
# Encoding path
## Incorporate information from t
h1 = self.conv1(x) + self.dense1(embed)
## Group normalization
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h2 = self.attn2(h2, y_embed)
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h3 = self.attn3(h3, y_embed)
# Decoding path
## Skip connection from the encoding path
h = self.tconv3(h3) + self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.attn6(h, y_embed)
h = self.tconv2(h + h2)
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hTraining our latent diffusion model
Finally, we will put everything together, and combine our latent space representation with our fancy U-Net for learning the score function. (This may not actually work that well…but at least you can appreciate that, with all these moving parts, this becomes a hard engineering problem.)
Run the cell below to train our latent diffusion model!
#@title Training Latent diffusion model
continue_training = True #@param {type:"boolean"}
if not continue_training:
print("initilize new score model...")
latent_score_model = torch.nn.DataParallel(
Latent_UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn,
channels=[4, 16, 32, 64], ))
latent_score_model = latent_score_model.to(device)
n_epochs = 250 #@param {'type':'integer'}
## size of a mini-batch
batch_size = 1024 #@param {'type':'integer'}
## learning rate
lr=1e-4 #@param {'type':'number'}
latent_data_loader = DataLoader(latent_dataset, batch_size=batch_size, shuffle=True, )
latent_score_model.train()
optimizer = Adam(latent_score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.5, 0.995 ** epoch))
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
for z, y in latent_data_loader:
z = z.to(device)
loss = loss_fn_cond(latent_score_model, z, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * z.shape[0]
num_items += z.shape[0]
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
# Print the averaged training loss so far.
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Update the checkpoint after each epoch of training.
torch.save(latent_score_model.state_dict(), 'ckpt_latent_diff_transformer.pth')Loss at ~55 after 600 epochs, pretty slow
digit = 4 #@param {'type':'integer'}
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 500 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
latent_score_model.eval()
## Generate samples using the specified sampler.
samples_z = sampler(latent_score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
x_shape=(4,10,10),
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
decoder_samples = ae_model.decoder(samples_z).clamp(0.0, 1.0)
sample_grid = make_grid(decoder_samples, nrow=int(np.sqrt(sample_batch_size)))
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
# play with architecturs
latent_score_model = torch.nn.DataParallel(
Latent_UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn,
channels=[4, 16, 32, 64], ))
latent_score_model = latent_score_model.to(device)
train_diffusion_model(latent_dataset, score_model,
n_epochs = 100,
batch_size = 1024,
lr=10e-4,
model_name="transformer_latent")Examine Samples
Below, we examine some samples in more detail to study the image generation quality. You may see some pretty weird stuff here.
cossim_mat = visualize_digit_embedding(latent_score_model.module.cond_embed.weight.data)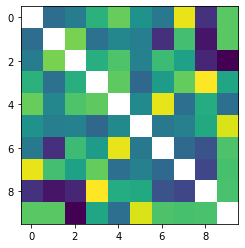
digit = 8 #@param {'type':'integer'}
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 250 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
latent_score_model.eval()
## Generate samples using the specified sampler.
samples_z = sampler(latent_score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
x_shape=(4,10,10),
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
decoder_samples = ae_model.decoder(samples_z).clamp(0.0, 1.0)
sample_grid = make_grid(decoder_samples, nrow=int(np.sqrt(sample_batch_size)))
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
def save_samples_latents(latent_score_model, suffix):
for digit in range(10):
sample_batch_size = 64 #@param {'type':'integer'}
num_steps = 250 #@param {'type':'integer'}
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
latent_score_model.eval()
## Generate samples using the specified sampler.
samples_z = sampler(latent_score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
x_shape=(4,10,10),
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
decoder_samples = ae_model.decoder(samples_z).clamp(0.0, 1.0)
sample_grid = make_grid(decoder_samples, nrow=int(np.sqrt(sample_batch_size)))
sample_np = sample_grid.permute(1, 2, 0).cpu().numpy()
plt.imsave(f"latent_diffusion{suffix}_digit%d.png"%digit, sample_np,)
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_np, vmin=0., vmax=1.)
plt.show()
save_samples_latents(latent_score_model, "_restanh") |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Save your progress!
%cp ckpt*.pth /content/drive/MyDrive/MLFS_StableDiffusionDemo
!du -sh ckpt*.pth
# %mkdir /content/drive/MyDrive/MLFS_StableDiffusionDemo/imgs
%cp *.png /content/drive/MyDrive/MLFS_StableDiffusionDemo/imgs