

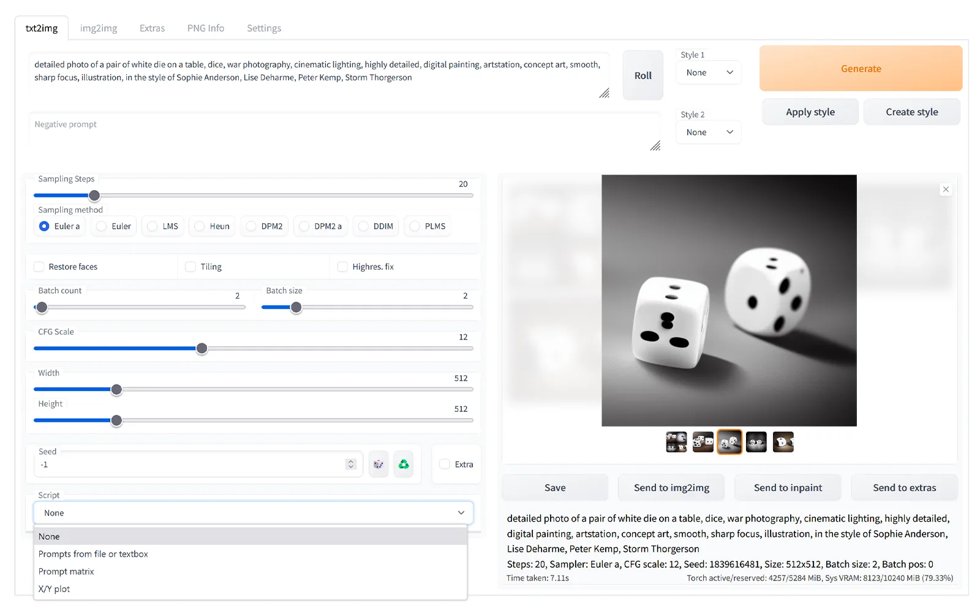
Stable Diffusion is an open-source text-to-image generative AI model that creates detailed images from natural language prompts. Built on a diffusion process, it starts with random noise and gradually refines it into a coherent image guided by the input text. Because it is released under a permissive license, developers and artists can run it locally, customize it, and fine-tune it for specific styles or use cases. This accessibility has made Stable Diffusion popular for digital art, concept design, marketing visuals, and creative experimentation.
Beyond basic text-to-image generation, Stable Diffusion supports advanced capabilities such as image-to-image transformation, inpainting (editing parts of an image), outpainting (extending images beyond their borders), and style customization through fine-tuned models and embeddings. It can be deployed on personal computers with capable GPUs or integrated into web applications and creative tools via APIs. Its open ecosystem and strong community support have led to a wide range of extensions, user interfaces, and specialized models tailored to different artistic and commercial needs.
.^.